Interindividual Variation Refuses to Go Away: A Bayesian Computer Model of Language Change in Communicative Networks
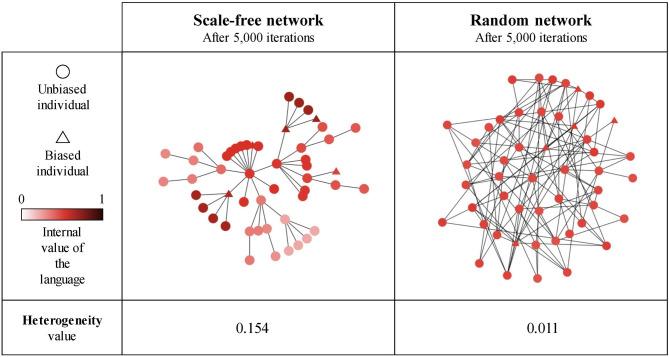
Treating the speech communities as homogeneous entities is not an accurate representation of reality, as it misses some of the complexities of linguistic interactions. Inter-individual variation and multiple types of biases are ubiquitous in speech communities, regardless of their size. This variation is often neglected due to the assumption that "majority rules," and that the emerging language of the community will override any such biases by forcing the individuals to overcome their own biases, or risk having their use of language being treated as "idiosyncratic" or outright "pathological." In this paper, we use computer simulations of Bayesian linguistic agents embedded in communicative networks to investigate how biased individuals, representing a minority of the population, interact with the unbiased majority, how a shared language emerges, and the dynamics of these biases across time. We tested different network sizes (from very small to very large) and types (random, scale-free, and small-world), along with different strengths and types of bias (modeled through the Bayesian prior distribution of the agents and the mechanism used for generating utterances: either sampling from the posterior distribution ["sampler"] or picking the value with the maximum probability ["MAP"]). The results show that, while the biased agents, even when being in the minority, do adapt their language by going against their a priori preferences, they are far from being swamped by the majority, and instead the emergent shared language of the whole community is influenced by their bias.